Failure prediction in innovative vehicle projects
a Supper & Supper Use Case

The development and the first market launch of very innovative vehicles with new technologies involves challenges, especially for the development of a quality management framework. There is no historic information and the pro-cess cannot be based on past experiences. For the quality management it is important to identify potential damage types and their drivers or patterns. For newly developed cars there is no previous field information where patterns of car configurations and error patterns lead to specific car failures.
The aim of this project was to develop an algorithm capable of identifying clusters of failure patterns and vehicle configurations leading to specific vehicle failures.
Each sample of the data consisted of information on the configuration of the individual car, data from the production process, the normalized log of the error messages from different control modules, text mined data from customer problem descriptions, repair reports and the current run-time of the car.
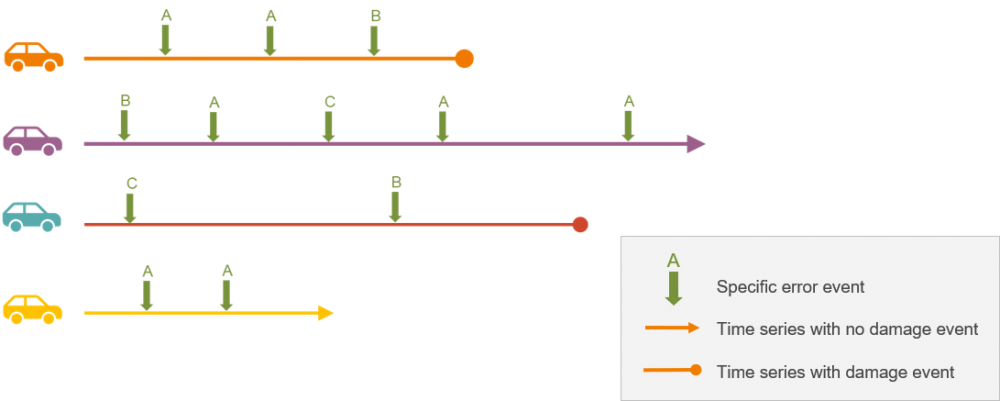
Most of the provided features were nominal data with categories of labels, which consisted of car records taken at different time points of their life cycle and many data points were censored. Additionally, there were couple of error source which might have biased the precision.
We implemented a feature engineering approach, which accounts for the different stages of the life cycle. The error event variables were re-engineered, so that they relate the relevance of a certain error event for an individual car with the corresponding relevance of the error event for all cars. The provided features were projected into the numerical space by applying Multiple Correspondence Analysis. The best algorithm was the DBSCAN, which was selected through the silhouette coefficient.
The developed dynamic algorithm can be used to identify clusters of common damage patterns, that were spread across different car configurations.
Cars in different stages of their life cycle can now be incorporated in the clustering.
Category
→ MECHANICAL ENGINEERING
→ Predictive Maintenance
Technologies
Clustering
Survival analysis
Hazard function
Term frequency
inverse document frequency




