Natural Language Processing auf einem Jobportal
ein Supper & Supper Use Case

Das Projekt basiert auf einem Datensatz von veröffentlichten Stellenausschreibungen, die durch Webcrawling ermittelt wurden.
Viele Jobportale untersagen das Webcrawlen. Zudem hat das verwendete Portal permanente Modifikationen an Quellcodes vorgenommen, was das Crawlen erheblich erschwerte.
Ein strukturierter Datensatz mit Beschreibungen von Positionen, Firmennamen, Standorten und Erscheinungsdaten wurde durch einen Python-basierten Web-Crawler erstellt. Die Datenbank stand als CSV-Datei zum Download zur Verfügung.
Die Berufsfelder und Kompetenzen wurden mit Hilfe des Dataturks-Tools gelabelt und im JSON-Format heruntergeladen.
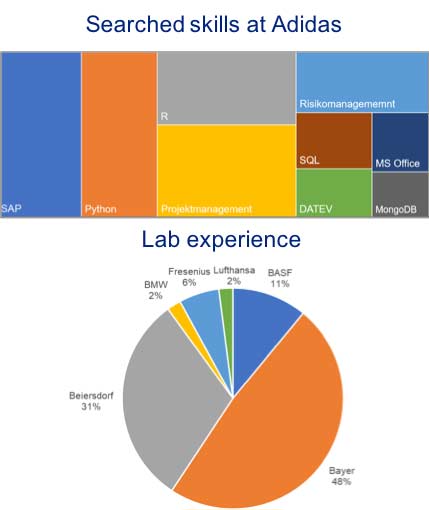
Die erzielten Ergebnisse werden in einem benutzerfreundlichen Dashboard dargestellt, so dass der Benutzer je nach Bedarf ein Unternehmen, Kompetenzen oder Berufsfelder betrachten kann. Die Filterung nach Unternehmen liefert ein Diagramm, in dem die Größe der Rechtecke der Anzahl der offenen Positionen im Unternehmen entspricht.
Durch die Auswahl einer bestimmten Qualifikation oder Berufserfahrung wird der Prozentsatz von offenen Positionen im jeweiligen Unternehmen angezeigt. Weitere Analysen, wie z.B. kombinierte Kompetenzen, können ebenfalls durchgeführt werden.
Der erstellte Algorithmus kann erweitert werden, um die große Anzahl von Bewerbungen zu scannen, die ein Unternehmen erhält.
Die Ergebnisse stellen eine einfache Lösung dar, um Ressourcen für Marktforschungsaktivitäten zu sparen.



