Beurteilung von Brustkrebstumoren mit Hilfe von Dataiku
ein Supper & Supper Use Case

Das Projektziel war die Entwicklung eines maschinellen Lernmodells zur Vorhersage der Qualität von Brusttumoren.
Es wurden zwei verschiedene Datensätze des Krankenhauses Wisconcin mit 570 und 700 Fällen verwendet. Der erste Datensatz basierte ausschließlich auf Daten der Zellenebene. Für jedes Bild wurden zehn Zellmerkmale mit dem entsprechenden Mittelwert, Standardfehler und “worst” (Mittelwert der drei größten Werte) berechnet. Der zweite Datensatz lieferte individuelle Werte von eins bis zehn von Zellattributen und Mitosestadien.
Beide Datensätze enthielten eine heterogene Verteilung von gutartigen und bösartigen Gruppen.
Aufgrund der Tatsache, dass die Ausgabegruppen bekannt waren, implementierten wir überwachte Lernalgorithmen wie das “random forest” und “logistic regression” Klassifikationsverfahren. Die Genauigkeit wurde als Metrik gewählt, um einen Vergleich zwischen den Leistungen der Algorithmen zu erhalten. Die Methode wurde mit Hilfe der Dataiku-Software durchgeführt.
Das “random forest” Verfahren erzielte eine Genauigkeit von 99,7 % und 99,3 %.
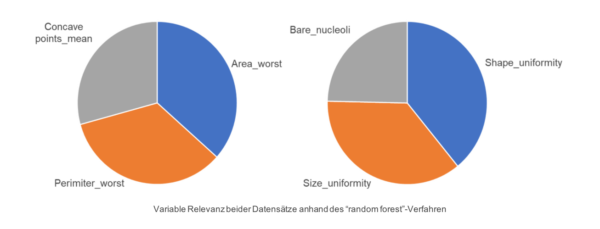
Mit Hilfe der “random forest”- Methode haben wir die Bedeutung der verwendeten Variablen beider Datensätze ermittelt. Für den ersten Datensatz waren die Mittelwerte der drei größten Werte entscheidend für die Vorhersage. Es war bemerkenswert, dass das Mitosestadium des zweiten Datensatzes keine Rolle für die Vorhersage spielte.
Die “logistic regression”- Methode wurde in beiden Fällen mit einer Genauigkeit von 99,6% durchgeführt. Die Konfusion Matrix, basierend auf dem optimierten F1-Score wurden gespeichert. Die falsche Prognose eines gutartigen Tumors anstelle von bösartig wurde höher eingestuft.
Der Grenzwert der Konfusion Matrix entsprach der Zahl, ab der die Vorhersage positiv war. Die Werte wurden auf 0,475 und 0,25 gesetzt.
Kategorie
Technologien
Dataiku
random forest
logistic regression




