Image-based Segmentation of Concrete Cracks
a Supper & Supper Use Case

We made use of a dataset of 458 high-resolution RGB pictures showing different concrete cracks.
Training a neural network requires a large amount of training data. For different applications the structures that need to be analyzed can differ greatly.
To further increase the performance of our model we made use of different augmentation techniques that can simulate various lighting conditions and structural variances. We applied the Deep Lab v3 neural network architecture, the current state-of-the-art in image segmentation. The model and training pipeline were implemented with PyTorch.
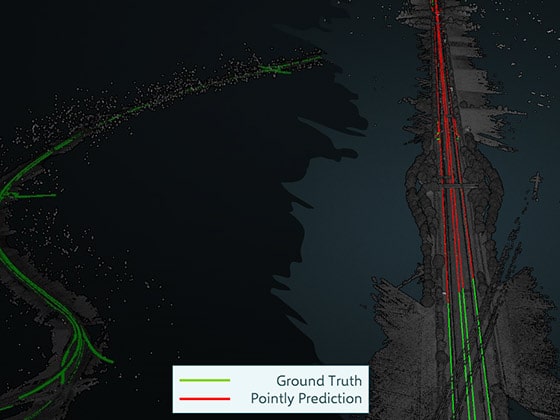
Model performance was evaluated based on the dice coefficient as well as true positive rate (TPR). The former indicates how well the predicted crack pixels align with the ground truth. TPR measures how many crack pixels were accurately detected by the model.
The final model achieved a dice coefficient of 88% and a TPR of 97% on the validation set. This performance is suitable for automated crack detection applications.
Predictions where then denoised using morphological opening. Stitching the tiles back together we could analyze the entire pictures regarding number of cracks as well as crack length and width.
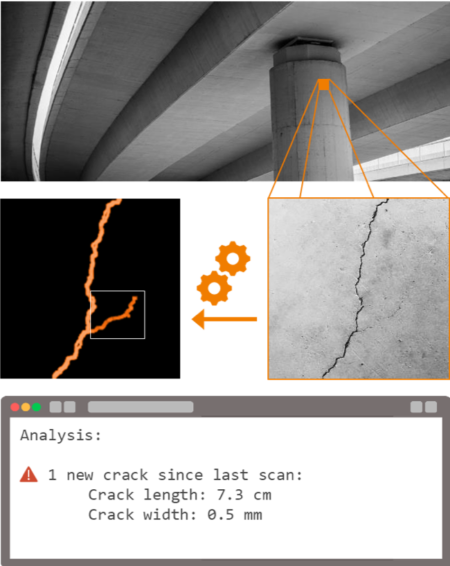
The tool is capable of accurately detecting surface cracks on pixel level. Crack width and length can thus be automatically monitored. For applications where images are consistently taken from the same locations, this allows analyzing changes in cracks and early detection of new cracks.
Category
→ GEO AI
→ Infrastructure
→ Predictive Maintenance
→ Deep Learning Object Detection
→ Spatial temporal Analysis
→ Computer Vision
Technologies
Deep Learning